1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
| import requests
import pandas as pd
import time
import tkinter as tk
from tkinter import simpledialog
def get_uploads_playlist_id(api_key, channel_id):
url = 'https://www.googleapis.com/youtube/v3/channels'
params = {
'key': api_key,
'id': channel_id,
'part': 'contentDetails'
}
response = requests.get(url, params=params)
data = response.json()
if 'items' in data and len(data['items']) > 0:
return data['items'][0]['contentDetails']['relatedPlaylists']['uploads']
else:
print("无法获取上传视频的播放列表 ID。")
return None
def get_video_urls_from_playlist(api_key, playlist_id):
base_url = 'https://www.googleapis.com/youtube/v3/playlistItems'
video_data = []
next_page_token = None
retries = 3
while True:
params = {
'key': api_key,
'playlistId': playlist_id,
'part': 'snippet',
'maxResults': 50,
'pageToken': next_page_token
}
for attempt in range(retries):
try:
response = requests.get(base_url, params=params)
response.raise_for_status()
break
except requests.exceptions.RequestException as e:
print(f"请求失败(尝试 {attempt + 1}/{retries} 次):{e}")
time.sleep(2)
else:
print("所有重试均失败,停止请求。")
return video_data
data = response.json()
if 'error' in data:
print(f"API 错误:{data['error'].get('message', '未知错误')}")
break
for item in data.get('items', []):
video_id = item['snippet']['resourceId']['videoId']
title = item['snippet']['title']
video_data.append([title, f"https://www.youtube.com/watch?v={video_id}"])
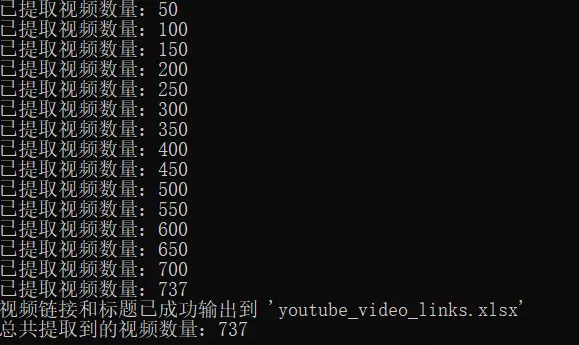
print(f"已提取视频数量:{len(video_data)}")
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
time.sleep(1)
return video_data
def save_to_excel(video_data):
df = pd.DataFrame(video_data, columns=["Title", "Video URL"])
df.to_excel("youtube_video_links.xlsx", index=False, engine='openpyxl')
print("视频链接和标题已成功输出到 'youtube_video_links.xlsx'")
def main():
root = tk.Tk()
root.title("批量提取YouTube视频信息")
root.geometry("450x250")
root.config(bg="#f4f4f9")
frame = tk.Frame(root, bg="#f4f4f9")
frame.pack(pady=20)
label_font = ('Arial', 10, 'bold')
entry_font = ('Arial', 10)
tk.Label(frame, text="请输入API密钥:", font=label_font, bg="#f4f4f9", anchor="w").grid(row=0, column=0, padx=20, pady=10, sticky="w")
api_key_entry = tk.Entry(frame, font=entry_font, width=35)
api_key_entry.grid(row=0, column=1, padx=10, pady=10)
tk.Label(frame, text="请输入频道ID:", font=label_font, bg="#f4f4f9", anchor="w").grid(row=1, column=0, padx=20, pady=10, sticky="w")
channel_id_entry = tk.Entry(frame, font=entry_font, width=35)
channel_id_entry.grid(row=1, column=1, padx=10, pady=10)
button_frame = tk.Frame(root, bg="#f4f4f9")
button_frame.pack(pady=20)
def on_submit():
api_key = api_key_entry.get()
channel_id = channel_id_entry.get()
if api_key and channel_id:
playlist_id = get_uploads_playlist_id(api_key, channel_id)
if playlist_id:
video_data = get_video_urls_from_playlist(api_key, playlist_id)
if video_data:
save_to_excel(video_data)
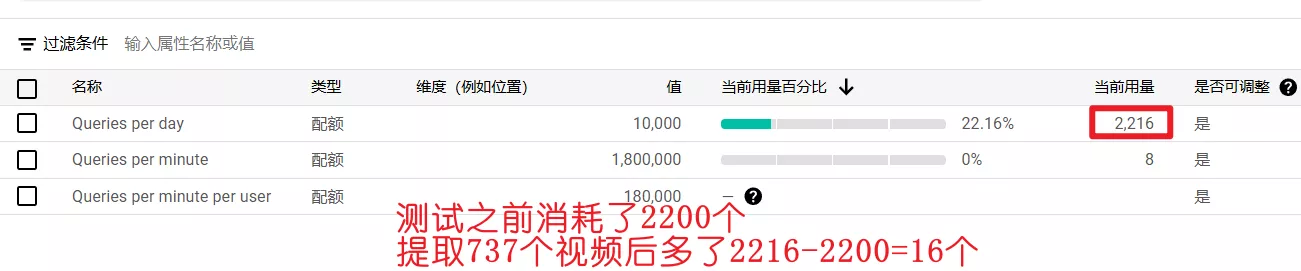
print(f"总共提取到的视频数量:{len(video_data)}")
else:
print("没有提取到任何视频链接")
else:
print("无法获取播放列表 ID")
else:
print("API密钥和频道ID不能为空")
root.quit()
def on_cancel():
root.quit()
submit_button = tk.Button(button_frame, text="提交", command=on_submit, font=('Arial', 10), width=12, bg="#4CAF50", fg="white", relief="raised")
submit_button.pack(side="left", padx=15)
cancel_button = tk.Button(button_frame, text="取消", command=on_cancel, font=('Arial', 10), width=12, bg="#f44336", fg="white", relief="raised")
cancel_button.pack(side="left", padx=15)
root.mainloop()
input("程序运行完毕,请按回车键退出...")
if __name__ == "__main__":
main()
|