
通过文件魔数识别文件真实类型
前言
有的时候从网络上下载的文件看似是 png 格式实际是 exe 或者其他伪装的格式,一旦打开或许就会中招;又或者下载的文件看似是 pdf 格式实际是 rar 格式,默认使用 pdf 工具打开必然是不行的,需要改成 rar 后缀再解压才能使用……
本期介绍下如何查看文件的真实类型。
文件魔数(Magic Number)是存储在文件头部的一组特定的二进制标识符,用于标记文件类型。通过检查文件的魔数,可以在不依赖文件扩展名的情况下识别文件类型。
Windows 查看文件魔数
- win+r,输入 cmd,打开命令提示符窗口。
- 运行以下命令:
1 | certutil -dump <文件路径> | more |
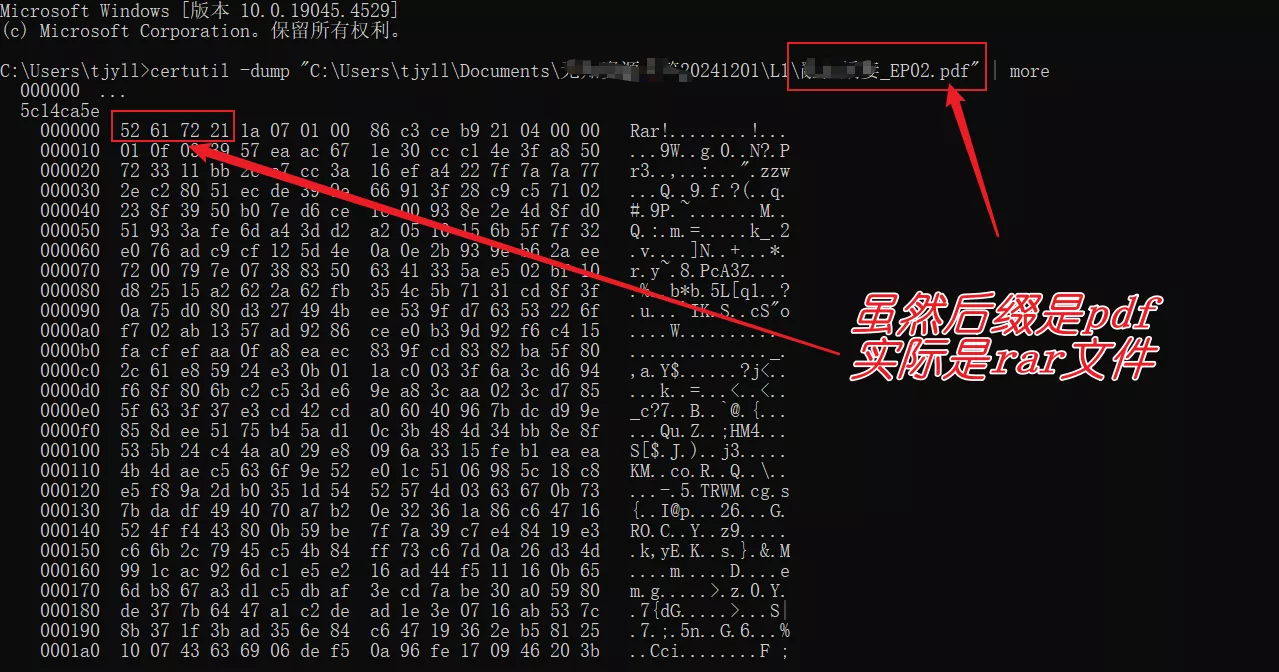
根据魔数判断文件类型。常见文件类型的魔数如下:
52 61 72 21(Rar!):RAR 压缩文件。50 4B 03 04:ZIP 压缩文件。FF D8 FF:JPEG 图片文件。89 50 4E 47:PNG 图片文件。
其他类型可以查阅 文件魔数列表—维基百科。
维基百科打不开的可以看这个文件魔数列表(部分)
python 查询
不使用第三方库
以下 python 代码的查询字段是从这个github 项目摘出来的。
github 访问不稳可以点击这里下载json 数据。
查询字段可自定义修改。
1 | import tkinter as tk |
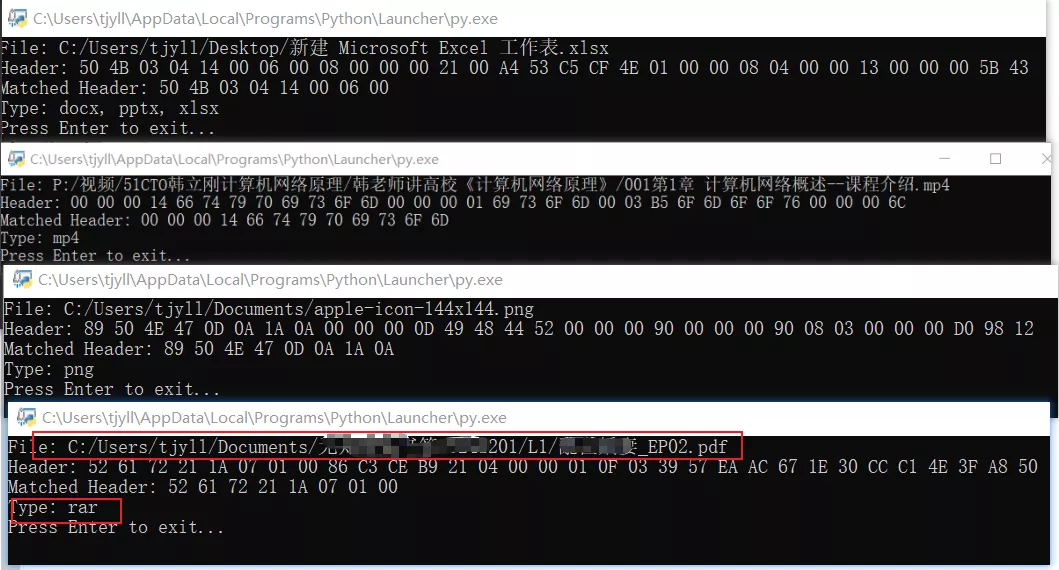
使用方法:确保已经安装好 python,新建文本文档,把代码复制进去,改后缀为 py,双击运行,选择文件后会输出信息
使用示例:
使用第三方库
- win10 推荐直接安装此版本
python-magic-bin,内置了所需的动态链接库
1 | pip install python-magic-bin |
- 也可安装
python-magic,但对于 win10 安装了python-magic后还需要下载并正确配置magic1.dll
1 | pip install python-magic |
Python 文件类型识别——python-magic_python magic-CSDN 博客
下载后解压,把 magic1.dll 放到D:\Python\Lib\site-packages\magic目录下;注意替换自己的 python 安装目录;
1 | import tkinter as tk |
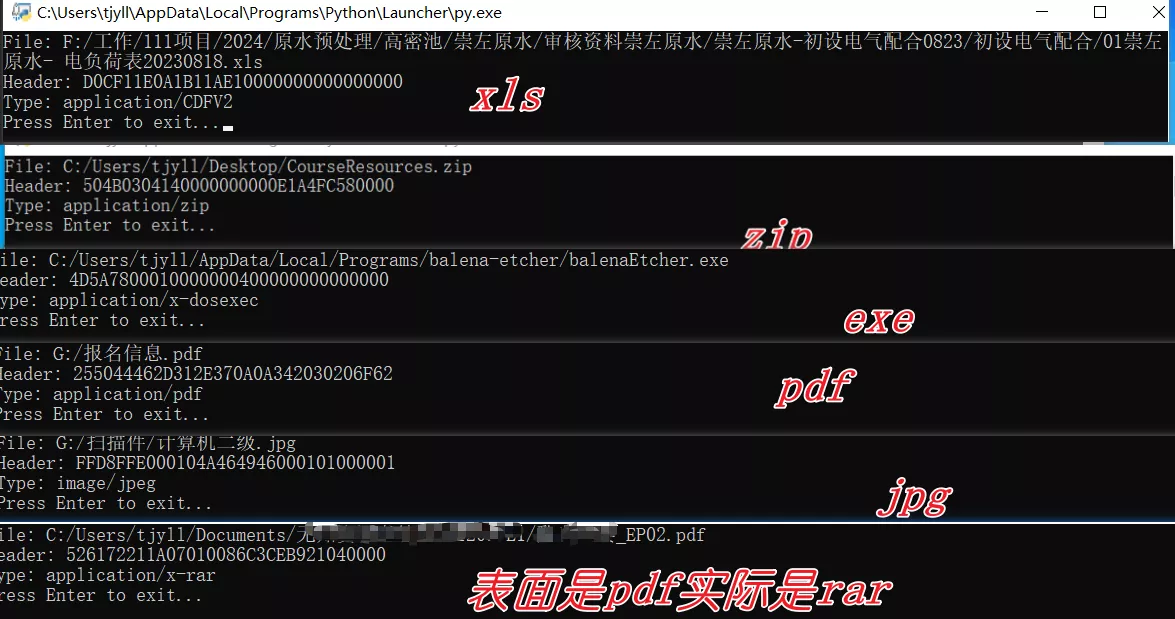
使用方法:确保已经安装好 python,新建文本文档,把代码复制进去,改后缀为 py,双击运行,选择文件后会输出信息。
使用示例:
注意:
输出的 type 类型如果不认识可以百度搜索;
新版本的 Office 文件(如 .xlsx、.docx、.pptx)采用的是 Open XML 格式,它们本质上是一个 ZIP 压缩包,所以使用此方法会被识别为 zip。
数据处理的流程
点击打开数据处理过程
处理 json
待处理数据的格式
从一个 JSON 文件中提取信息,JSON 文件部分内容如下:
1 | { |
- 结构说明:
- 外层是一个字典,键是文件类型(如
"123"、"cpl")。 - 每个键对应一个字典,其中包含:
signs:一个列表,存储字符串,格式为"offset,signature"。mime:文件的 MIME 类型。
- 外层是一个字典,键是文件类型(如
完整 json 数据下载,下载后改文件名为input.json;json 源数据地址:github 项目
处理目标结果
目标是将 signs 中的每个 signature 和外层键组合,输出到一个文本文件中。格式如下:
1 | '00001A00051004': '123', |
'signature'是从signs中提取的签名值。'123'、'cpl'等是外层键值。
分析
- 处理逻辑:
- 读取 JSON 数据:将文件解析为 Python 的字典。
- 遍历字典:访问每个键值对,处理
signs字段。 - 分割字符串:通过
split(',')提取offset和signature,这里只需要signature。 - 格式化输出:将
signature和外层键组合为字符串并写入文件。
- 边界条件:
- 如果
signs不存在或为空,不处理。 signs中的字符串格式必须为offset,signature,否则可能报错。
- 如果
语法
以下是用到的主要语法和功能:
文件操作(
open函数):- 读取文件:
open(file_path, 'r', encoding='utf-8') - 写入文件:
open(file_path, 'w', encoding='utf-8') - 推荐用
with管理文件资源,确保自动关闭文件。
- 读取文件:
JSON 数据解析(
json.load函数):- 将 JSON 格式的内容转换为 Python 的字典。
- 例如,
{"key": "value"}在 Python 中表示为{"key": "value"}。
字典遍历:
使用
for key, value in dict.items()遍历字典的键值对。示例:
1
2
3data = {"a": 1, "b": 2}
for key, value in data.items():
print(key, value)
字符串分割(
split方法):用指定分隔符将字符串分割成列表。
示例:
1
2
3text = "0,00001A00051004"
parts = text.split(",")
print(parts) # ['0', '00001A00051004']
条件判断(
if语句):- 确保数据满足处理条件。
- 例如,
if 'signs' in value and value['signs']:检查value中是否有signs且不为空。
字符串格式化(f-string):
用
f"{变量}"插入变量到字符串中。示例:
1
2
3
4key = "123"
signature = "00001A00051004"
formatted = f"'{signature}': '{key}',"
print(formatted) # 输出: '00001A00051004': '123',
完整代码
以下是处理逻辑的完整代码:
1 | import json |
运行结果
执行后,output.txt 文件的内容为:
1 | '00001A00051004': '123', |
数据去重
对上面输出的output.txt文件进行去重。
文件部分内容如下
1 | '504B0304': 'odp', |
处理后的结果:
1 | '504B0304': 'odp, odt, ott', |
完整代码
1 | # 读取和处理 txt 文件,将结果写入新的 txt 文件 |
读取文件内容
1 | lines = file.readlines() |
读取所有行,lines 的值为:
1 | [ |
逐行处理数据
1 | for line in lines: |
第一行处理:'504B0304': 'odp',
line = "'504B0304': 'odp'"key, value = line.split(': ')->key = "'504B0304'",value = "'odp'"key.strip("'")->key = "504B0304"value.strip("'")->value = "odp"
merged_result 的更新:
1 | { |
第二行处理:'504B0304': 'odt',
line = "'504B0304': 'odt'"key = "504B0304",value = "odt"key已存在于merged_result中,将value添加到集合:
1 | { |
第三行处理:'504B0304': 'ott',
line = "'504B0304': 'ott'"key = "504B0304",value = "ott"key已存在于merged_result中,将value添加到集合:
1 | python复制代码{ |
第四行处理:'504B030414000600': 'pptx',
line = "'504B030414000600': 'pptx'"key = "504B030414000600",value = "pptx"key不存在于merged_result中,新建集合并添加值:
1 | { |
第五行处理:'504B030414000600': 'xlsx',
line = "'504B030414000600': 'xlsx'"key = "504B030414000600",value = "xlsx"key已存在于merged_result中,将value添加到集合:
1 | { |
第六行处理:'504B030414000600': 'docx',
line = "'504B030414000600': 'docx'"key = "504B030414000600",value = "docx"key已存在于merged_result中,将value添加到集合:
1 | { |
最终结果
1 | { |
合并和排序值
1 | final_result = {key: ', '.join(sorted(values)) for key, values in merged_result.items()} |
- 将集合转换为逗号分隔的字符串,并按字母顺序排序:
1 | { |
写入新文件
1 | with open(output_file, 'w', encoding='utf-8') as file: |
写入到 output.txt 文件的内容:
1 | '504B0304': 'odp, odt, ott', |
语法:
with open()
语法:
1
with open(file, mode, encoding) as f:
作用:
用于打开文件并确保操作完成后自动关闭文件。
mode
指定文件操作模式,如:
'r':读取模式(默认)。'w':写入模式(覆盖原内容)。'a':追加模式。encoding指定编码,常用utf-8。
示例:
1
2with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()readlines()
语法:
1
lines = file.readlines()
作用:
- 按行读取整个文件内容,返回一个包含每一行的列表。
示例: 假设
example.txt内容如下:1
2
3line 1
line 2
line 3运行以下代码:
1
2
3with open('example.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
print(lines)输出:
1
['line 1\n', 'line 2\n', 'line 3\n']
strip()
语法:
1
string.strip([chars])
作用:
- 去掉字符串两边的指定字符(默认为空格和换行符
\n)。
示例:
1
2
3line = " 'key': 'value',\n "
line = line.strip()
print(line) # 输出 "'key': 'value',"常用形式:
strip(','):去掉两边的逗号。rstrip():只去掉右侧字符。lstrip():只去掉左侧字符。
- 去掉字符串两边的指定字符(默认为空格和换行符
split()
语法:
1
string.split(separator, maxsplit)
作用:
- 按指定的分隔符将字符串拆分成列表。
示例:
1
2
3
4line = "'key': 'value'"
key, value = line.split(': ')
print(key) # 输出 "'key'"
print(value) # 输出 "'value'"- 默认用空格分割:
split()。 maxsplit指定分割次数。
if 条件语句
语法:
1
2
3
4if condition:
# 条件为真执行
else:
# 条件为假执行示例:
1
2
3
4
5
6
7key = '504B0304'
merged_result = {}
if key in merged_result:
print("Key exists.")
else:
print("Key does not exist.")输出:
1
Key does not exist.
字典操作
语法:
- 创建字典:
1
dictionary = {'key1': 'value1', 'key2': 'value2'}
- 检查键是否存在:
1
2if key in dictionary:
print("Key exists.")- 添加键值:
1
dictionary[key] = value
- 合并值(本代码中):
1
2
3
4if key in dictionary:
dictionary[key].add(value)
else:
dictionary[key] = {value}本代码中:
- 如果键存在,添加值到集合中(防止重复)。
- 如果键不存在,新建集合并存入值。
集合(set)
作用:
- 无序、唯一的元素集合,适合去重操作。
常用操作:
- 创建集合:
1
my_set = {'a', 'b'}
- 添加元素:
1
my_set.add('c') # {'a', 'b', 'c'}
- 去重:
1
2my_list = [1, 2, 2, 3]
unique = set(my_list) # {1, 2, 3}字典推导式
语法:
1
{key: value for key, value in iterable}
作用:
- 一种简洁的方式生成字典。
本代码中:
1
final_result = {key: ', '.join(sorted(values)) for key, values in merged_result.items()}
分解:
merged_result.items():获取字典中的键值对。sorted(values):对集合中的值排序。', '.join(...):将列表用逗号连接成字符串。
文件写入(write)
语法:
1
file.write(content)
作用:
- 将内容写入文件,字符串需指定写入格式。
示例:
1
2with open('output.txt', 'w', encoding='utf-8') as file:
file.write("'key': 'value',\n")格式化字符串
语法:
1
f"内容 {变量}"
作用:
- 将变量插入字符串。
本代码中:
1
file.write(f"'{key}': '{values}',\n")
将字典的键值对格式化写入文件。









