前言 本期分享chatgpt写的python脚本。功能:通过自动化操作浏览器和模拟鼠标点击,从指定的影视剧集 URL 中批量提取视频源链接,方便后续批量下载。根据输入剧集 URL 和总集数后,配合猫抓插件,程序会依次访问每个剧集页面,模拟鼠标点击并复制猫抓解析出的链接,最后将提取到的链接保存到文件中。
注意事项
浏览器类型 :
脚本默认使用 Google Chrome 。确保该浏览器已安装并能够正常运行。
浏览器安装位置 :
脚本中使用了 Chrome 浏览器的路径 C:\Program Files\Google\Chrome\Application\chrome.exe。如果 Chrome 安装在其他路径,请相应修改脚本中 chrome_path 变量为正确的安装路径。
浏览器插件 :
运行时浏览器窗口在最前层。
准备环境:
确保已经安装了 Python 3.x。
安装脚本依赖的第三方库。在命令行中运行:
1 pip install pynput pyautogui pyperclip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 from pynput import mouse, keyboardimport subprocessimport timeimport pyautoguiimport pyperclipimport reimport tkinter as tkfrom tkinter import simpledialogmouse_positions = [] def on_click (x, y, button, pressed ): if pressed and button == mouse.Button.left: mouse_positions.append((x, y)) print (f"第 {len (mouse_positions)} 次点击的位置: ({x} , {y} )" ) if len (mouse_positions) >= 2 : return False return True listener = mouse.Listener(on_click=on_click) listener.start() print ("请单击两次鼠标左键以记录位置..." )listener.join() if len (mouse_positions) < 2 : print ("未记录到足够的点击位置,程序退出。" ) exit() first_click_position = mouse_positions[0 ] second_click_position = mouse_positions[1 ] print ("记录的点击位置已应用到程序。" )def move_and_click (position ): controller = pyautogui controller.moveTo(position) time.sleep(0.5 ) controller.click() class CustomDialog (simpledialog.Dialog): def body (self, master ): tk.Label(master, text="请输入剧集URL:" ).grid(row=0 , column=0 ) self.url_entry = tk.Entry(master, width=50 ) self.url_entry.grid(row=0 , column=1 ) tk.Label(master, text="请输入总集数:" ).grid(row=1 , column=0 ) self.total_entry = tk.Entry(master, width=50 ) self.total_entry.grid(row=1 , column=1 ) return self.url_entry def apply (self ): self.url = self.url_entry.get() try : self.total_episodes = int (self.total_entry.get()) except ValueError: self.total_episodes = None def get_user_input (): root = tk.Tk() root.withdraw() dialog = CustomDialog(root, title="批量解析视频" ) if not dialog.url or dialog.total_episodes is None : print ("输入无效,脚本退出。" ) exit() return dialog.url, dialog.total_episodes chrome_path = r"C:\Program Files\Google\Chrome\Application\chrome.exe" exit_flag = False start_time = time.time() links_count = 0 def on_press (key ): global exit_flag try : if key.char == 'q' : exit_flag = True return False except AttributeError: pass listener = keyboard.Listener(on_press=on_press) listener.start() input_url, total_episodes = get_user_input() pattern = re.compile (r"(.*?)(\d+)(\.html)$" ) match = pattern.match (input_url)last_copied_link = input_url if match : base_url_part = match .group(1 ) first_episode = int (match .group(2 )) suffix = match .group(3 ) base_url = f"{base_url_part} {{}}{suffix} " episode_range = range (first_episode, 1 + total_episodes) else : print ("输入的 URL 格式无效" ) exit() for i in episode_range: if exit_flag: break url = base_url.format (i) process = subprocess.Popen([chrome_path, url]) time.sleep(3 ) move_and_click(first_click_position) time.sleep(0.5 ) move_and_click(second_click_position) time.sleep(0.5 ) copied_link = pyperclip.paste() retry_count = 0 refresh_count = 0 while copied_link == last_copied_link: time.sleep(1 ) move_and_click(first_click_position) move_and_click(second_click_position) time.sleep(0.5 ) copied_link = pyperclip.paste() retry_count += 1 if retry_count > 3 : if refresh_count < 3 : print ("剪贴板内容未更新,刷新页面并重试..." ) pyautogui.hotkey('ctrl' , 'r' ) time.sleep(3 ) move_and_click(first_click_position) move_and_click(second_click_position) retry_count = 0 refresh_count += 1 time.sleep(0.5 ) copied_link = pyperclip.paste() else : print ("刷新超过 3 次,剪贴板内容仍未更新,跳过当前页面。" ) with open ("copied_links.txt" , "a" ) as file: file.write(f"第 {i} 集:未提取到链接,请手动获取。\n" ) break if exit_flag: break if copied_link != last_copied_link: last_copied_link = copied_link print (f"复制的链接: {copied_link} " ) with open ("copied_links.txt" , "a" ) as file: file.write(f"第 {i} 集:{copied_link} \n" ) links_count += 1 else : print ("剪贴板内容未更新,跳过写入。" ) time.sleep(0.5 ) pyautogui.hotkey('ctrl' , 'w' ) time.sleep(0.5 ) if exit_flag: break end_time = time.time() total_time = end_time - start_time average_time = total_time / links_count if links_count > 0 else 0 print (f"总共提取了 {links_count} 条链接" )print (f"总耗时: {total_time:.2 f} 秒" )print (f"平均每条耗时: {average_time:.2 f} 秒" )input ("按回车键退出程序..." )
运行脚本
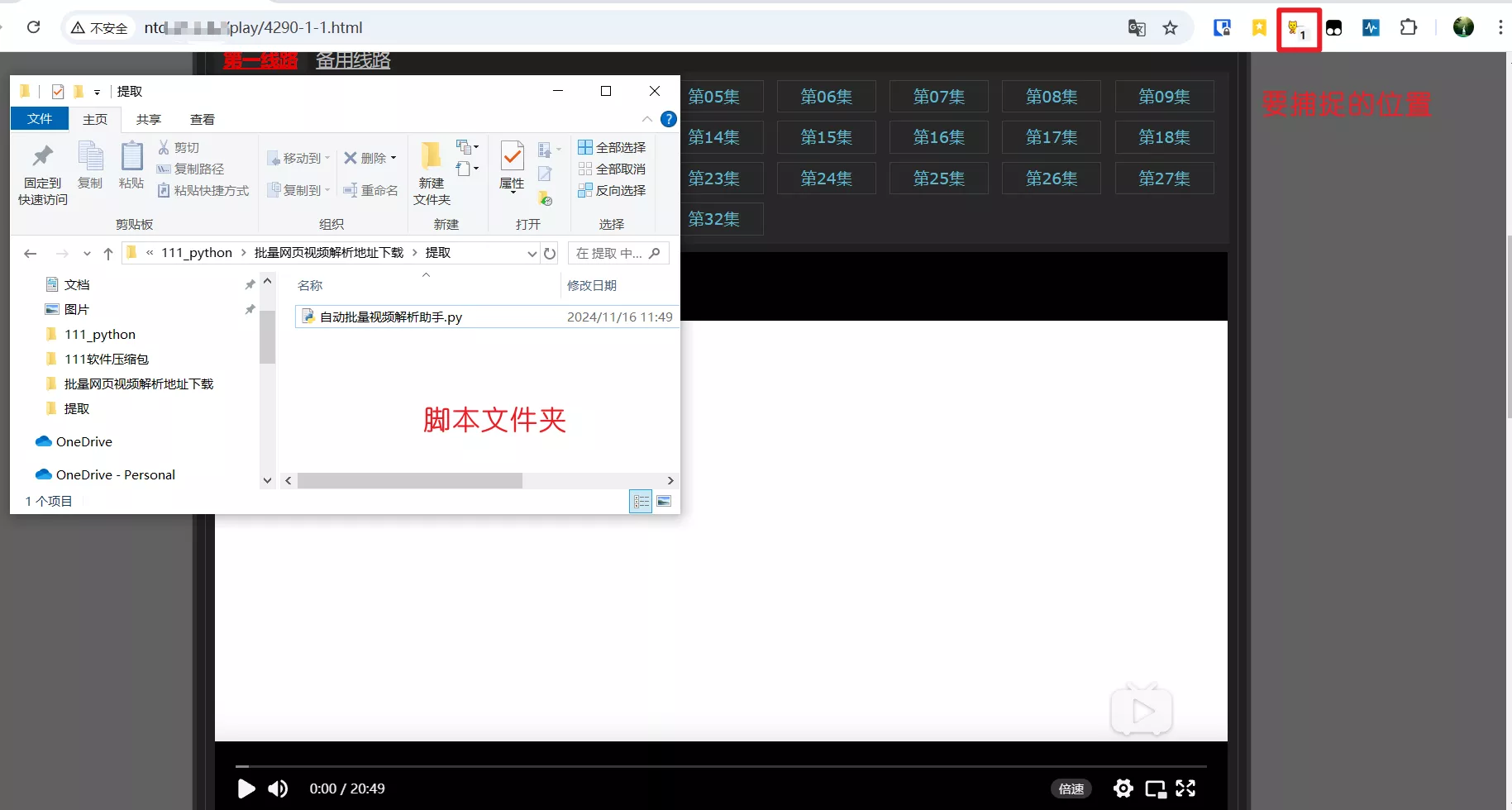
先打开浏览器;进入要批量提取的剧集网页;打开脚本所在文件夹并把窗口缩小,大致如下
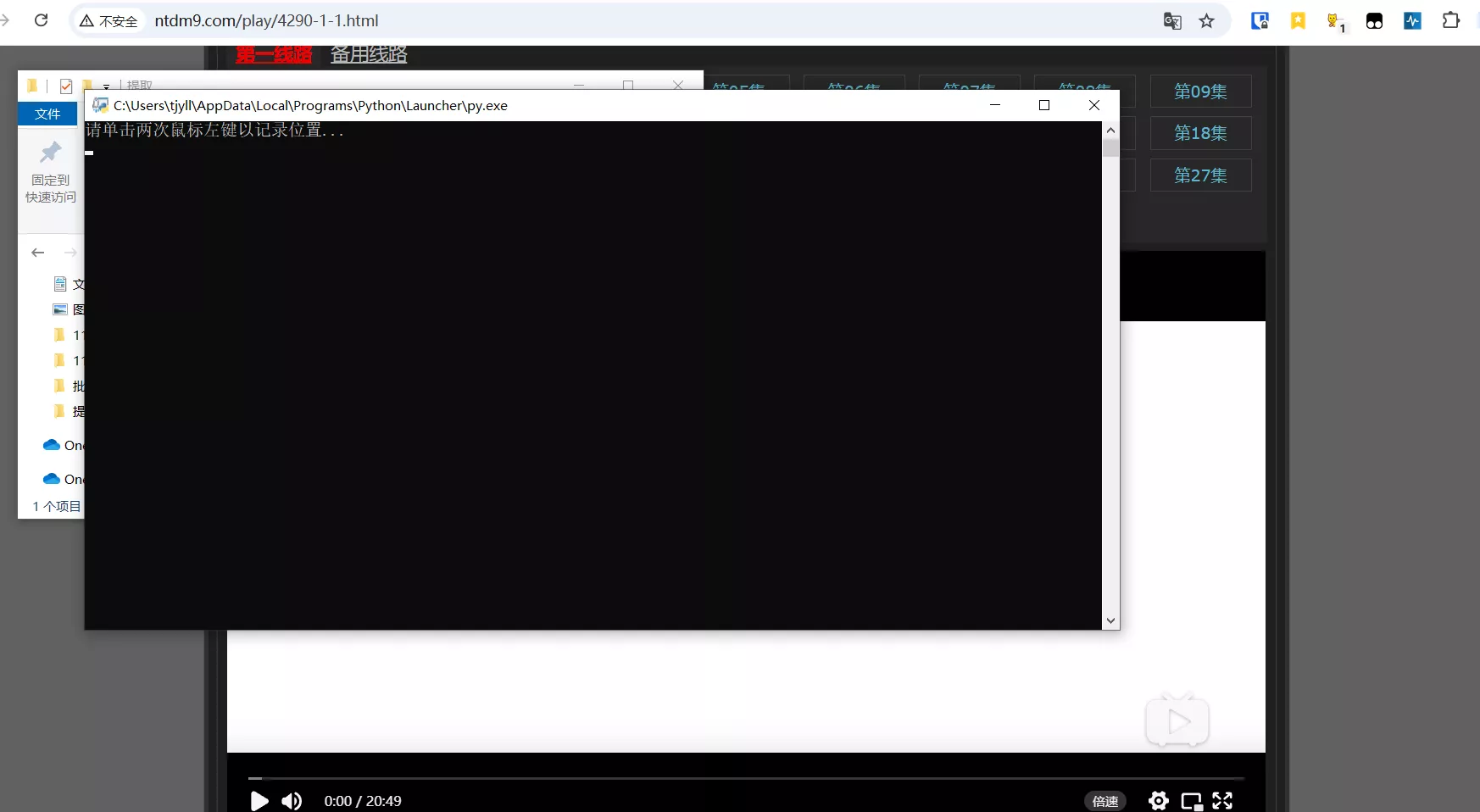
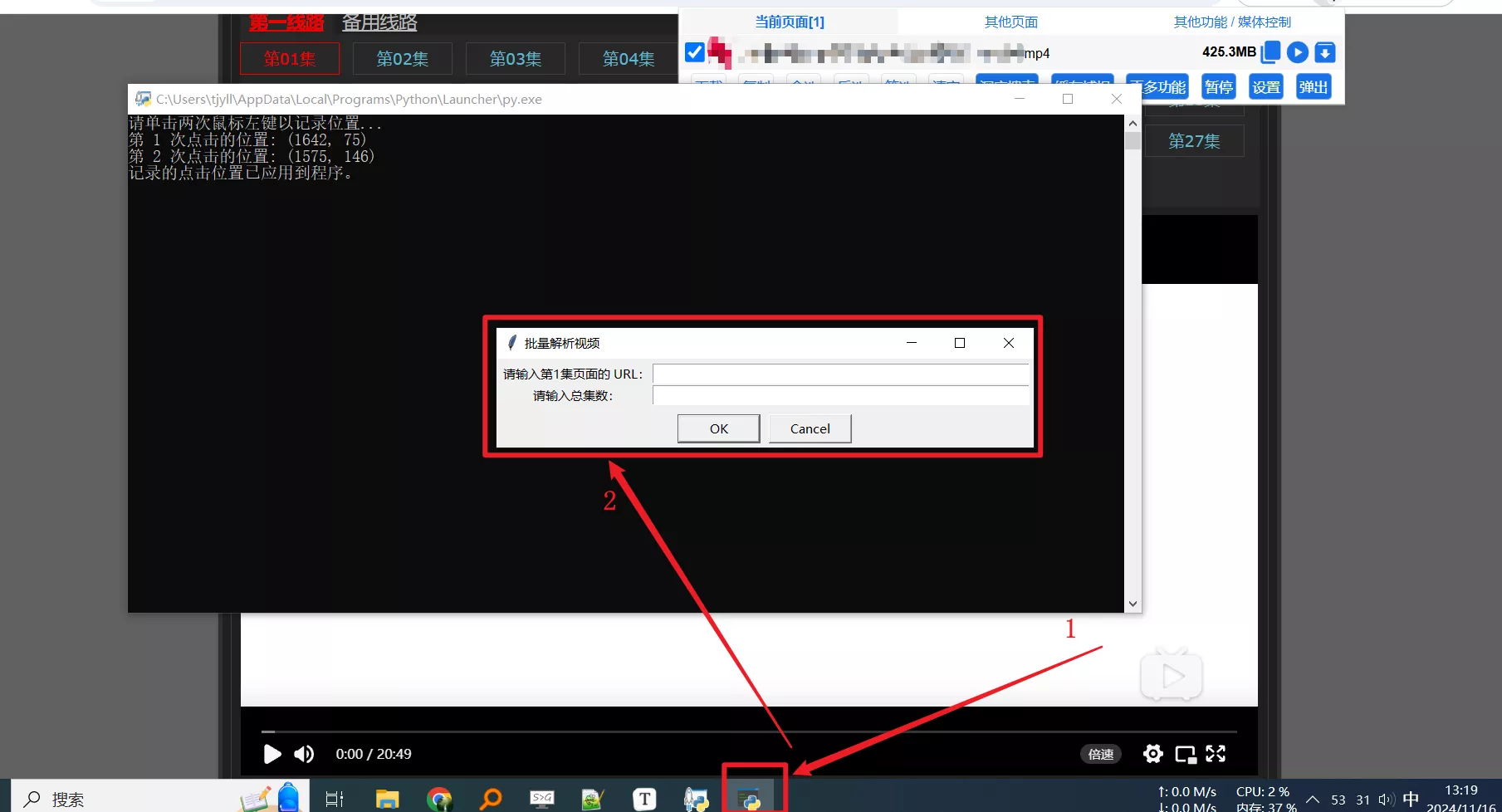
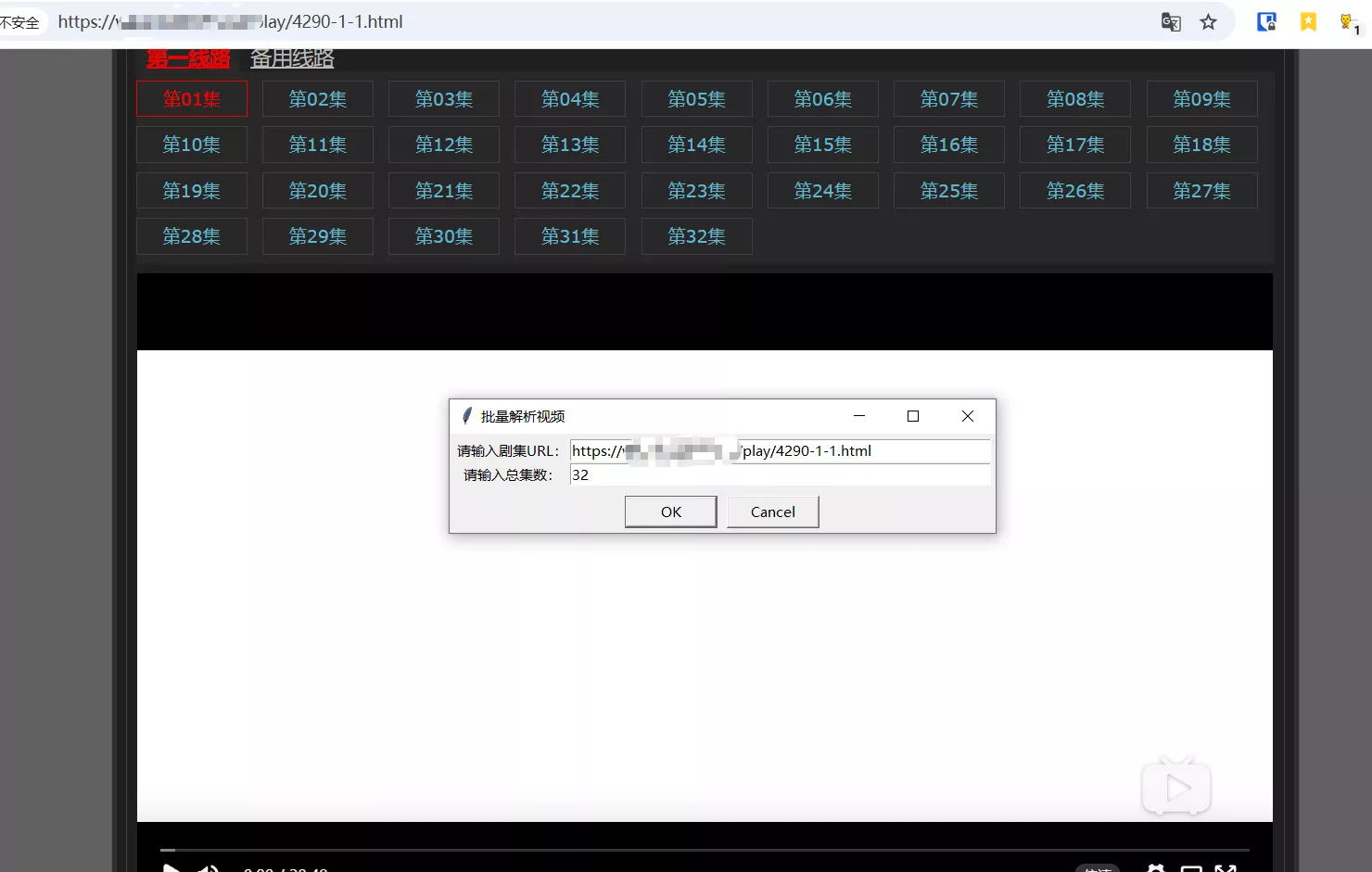
双击运行自动批量视频解析助手.py;出现如下窗口,鼠标不要随意点,它会记录接下来两次左键的位置。
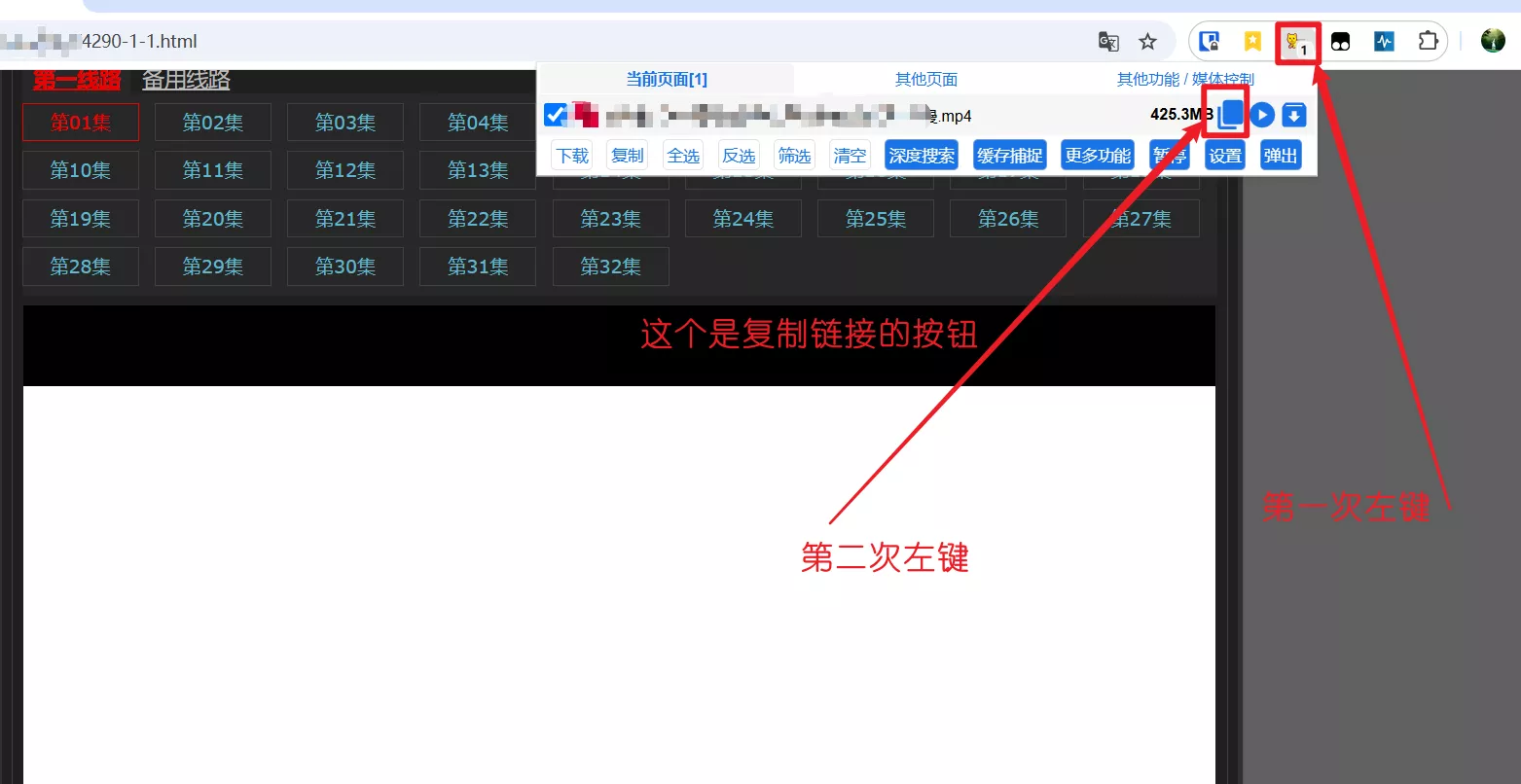
两次点击后注意底部任务栏;点击任务栏对话框图标,会在屏幕显示输入框。
停止程序:在程序运行过程中,按下 q 键
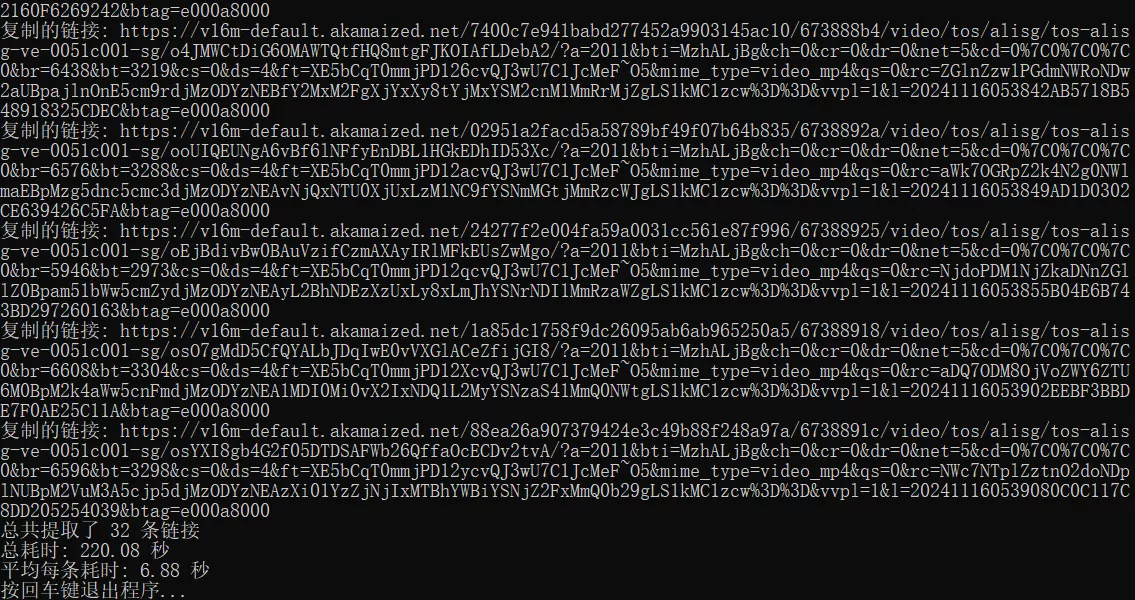
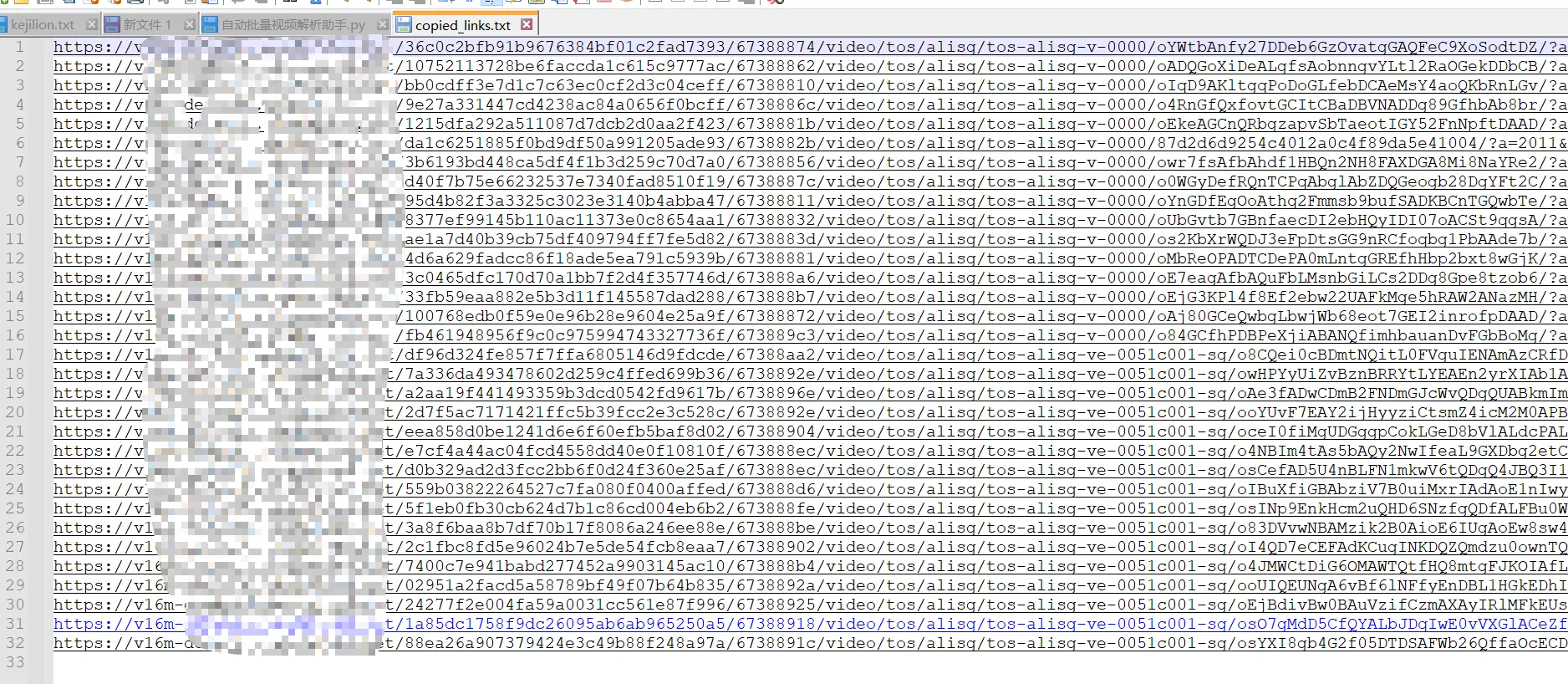
执行完成后,查看 copied_links.txt 文件,里面包含所有已复制的链接。
控制台会输出总链接数、总耗时及平均每条链接解析的时间。
注意事项:抓取下的直链具有有效期,尽快使用